【CO】P5课下--流水线CPU
本文为P5课下流水线CPU的设计思路和具体细节,仅供参考。
写在前面
进入P5,计组实验进入了流水线环节,搭完流水线和写这篇文章相隔两周(多谢P3课下的RAM给了我这次机会),这两周真是给自己放了一个长假。神经高度紧张后的放松是十分必要的,连续好几周的计组实在让我心力交瘁。不过太过放松自然也不是好事,就像现在,我的P5设计文档刚开始写,评测机也没有搭,理论作业今晚ddl,不过我还是有信心完成的(评测机够呛了,留到P6吧)。
【CO】P5课下–流水线CPU
总体设计思路
在流水线CPU的搭建这部分,我认为最重要的是理解流水线的工作机制:1.每一流水级同一周期内执行的指令是不同的。2.每到一流水级,获取自己需要的数据(上一级传递,转发与阻塞),每离开一流水级,把自己的东西全部打包打走(传递到下一级)。只要能准确地做到这两件事,就可以实现流水线的流动。和之前的单周期CPU相比,区别我们可以从两个方面去看:物理结构上区分了流水级,指令并且无论是否需要在某一流水级实现功能,都必须流过,并且是单向的;数据通路上不同流水级之间相互影响,数据需要在不同流水级之间传递,传递方向不是单向的。基于这样的特点,我们在介绍物理结构时以流水级为单位,在介绍数据通路时以指令为单位,重点关注指令在每个流水级的行为。
指令集合
与P4相同,课下提交要求实现的指令包括add(u),sub(u),ori,lui,beq,lw,sw,nop,j,jal,jr。在此基础上添加了移位指令sll。分类如下:
| R型指令 | I型指令 | J型指令 |
|---|---|---|
| add(u),sub(u),sll(nop),jr | ori,lui,beq,lw,sw | j,jal |
模块设计
之前的CPU模块包括:PC,IM,NPC,GRF,EXT,ALU,DM,CTRL等模块。流水线部分为了清晰地区分流水级,我们做出调整,将PC和IM合并作为F(Fetch)级的IFU模块;添加一个CMP模块,负责分支指令的比较(之前这部分是在ALU通过减法判断的,为了流水线的效率我们将CMP提取出来),与NPC,GRF,EXT构成D(Decode)级。ALU构成E(Execute)级,DM构成M(Memory)级。同时还有W(Write Back)回写级,将数据回写入GRF内,所以可以认为GRF既是D级元件也是W级元件。
同时,为了实现数据在流水线间的流动传递,在两流水级之间我们都要有一个流水线寄存器,负责接收上一流水级传递来的数据。所以抽象一下,我们的流水线寄存器其实就是这样:F | D | E | M | W。
对于CTRL,我们有两种选择,一是分布式译码,每一流水级都对CTRL进行实例化,获取在该流水级需要的数据,这样做的好处是在数据流水时只需要把指令和在该级获得的数据流水,而不需要把大量的控制信号流水,缺点是需要多次实例化控制器。二是集中式译码,在D级便将所有控制信号全部得出,优点在于只需要实例化一次控制器,缺点在于控制信号需要随指令一直流水传递。我认为,对于课程要求来说,分布式译码便于我们添加指令,如果有新的指令需要我们在某一级之后才能判断信号的值,分布式译码会让这样的过程更清晰;同时如果有新的控制信号出现,采用集中式译码需要在每一级流水线寄存器都添加新的端口;再加上我不喜欢把太多数据流水下去,更希望模块化独立化减少流水级之间的耦合,便于debug,所以选择采用分布式译码。当然,译码方式的选择仁者见仁,根据自己的喜好选择即可。
以上的模块我们之前都接触过,除此之外我们还需要一个STALL模块来控制阻塞信号的产生,用来处理数据冒险,具体内容我们在下面介绍。
综上我们的模块包括IFU,NPC,GRF,CMP,EXT,ALU,DM,CTRL,STALL,以及各流水线寄存器。顶层模块为mips,在模块命名和顶层进行模块实例化时,我们采用以下命名规则:
- 模块命名为
大写流水级_大写模块名,如:D_CMP,E_ALU。特别的,阻塞器和控制器模块分别为STALL和CTRL。 - 流水线寄存器命名为
大写两流水级_REG,如EM_REG。 - 模块实例化时命名为小写模块名,如
ifu,npc。特别的,阻塞器实例化名称为Stall,控制器实例化名称为大写流水级_ctrl,如:D_ctrl,E_ctrl。 - 流水线寄存器实例化命名为
大写两流水级_reg,如DE_reg。
总体结构如下: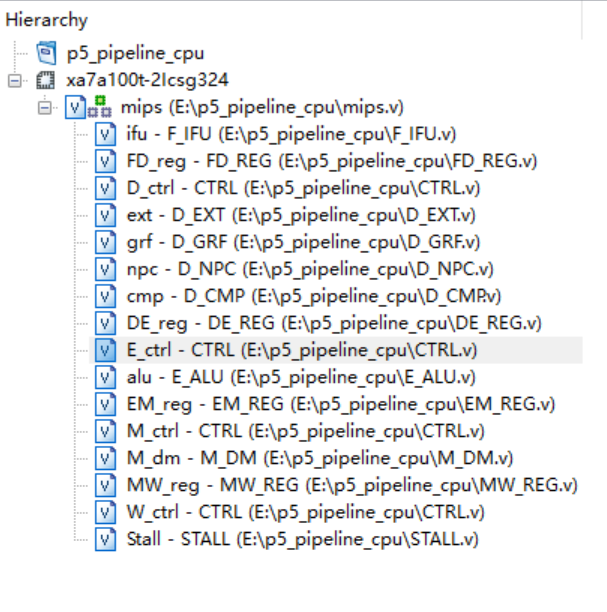
数据通路
除了一般的流水通路外,我们还需要转发和阻塞的策略来处理冒险情况的发生。转发的情况可以这样理解:需要的数据已经产生,不过在更后面的流水级中,这时候通过旁路转发便可以获得数据。阻塞的情况是:需要的数据还未产生,此时我们必须要阻塞流水线,直到需要的数据产生。我们采用AT法进行判断,具体内容我们在后面介绍。
具体模块设计
F级
F_IFU
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| npc | input | [31:0] | 下一条指令(未加0x00003000) |
| pc_we | input | pc是否可继续 | |
| pc | output | [31:0] | 当前指令pc(加了0x00003000) |
| instr | output | [31:0] | 当前指令的机器码 |
FD_REG
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| F_pc | input | [31:0] | 接收F的pc值 |
| F_instr | input | [31:0] | 接收F的机器码 |
| FD_we | input | 是否要更新寄存器中的值(阻塞冻结) | |
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| D_pc | output | [31:0] | 传递给D级的pc |
| D_instr | output | [31:0] | 传递给D级的instr |
当FD_we为0时,此时FD_REG被冻结,这样设计是满足阻塞的需要。
D级
D_EXT
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| in | input | [15:0] | 输入需要扩展的16位立即数 |
| EXTOp | input | 选择符号扩展或是0扩展 | |
| ans | output | [31:0] | 输出扩展结果 |
控制信号
| 信号 | 功能 |
|---|---|
| 1’b0 | 0扩展 |
| 1’b1 | 符号扩展 |
D_GRF
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| A1 | input | [4:0] | rs的编号 |
| A2 | input | [4:0] | rt的编号 |
| WR | input | [4:0] | 写入的寄存器的编号 |
| WD | input | [31:0] | 写入的数据 |
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| grf_we | input | grf写入使能 | |
| W_pc | input | [31:0] | W级的pc值 |
| RD1 | output | [31:0] | 读到的rs值 |
| RD2 | output | [31:0] | 读到的rt值 |
注意事项
- GRF有关于写的操作,数据都要来自于W级,读操作的数据来自D级,读写是分离的。
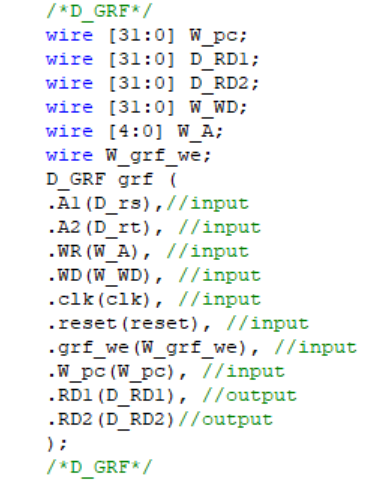
- GRF的读操作,读出的数据需要进行内部转发,即W级向D级的转发。

D_NPC
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| D_pc | input | [31:0] | 当前D级的pc |
| F_pc | input | [31:0] | 当前F级的pc |
| zero | input | rs和rt的值是否相等 | |
| ra_data | input | [31:0] | jr时回到的寄存器的值 |
| imm16 | input | [15:0] | 16位立即数 |
| imm26 | input | [25:0] | 26位立即数 |
| npc_op | input | [1:0] | 选择npc来源 |
| npc | output | [31:0] | 输出npc的值(未加0x00003000) |
控制信号
| 信号 | 功能 |
|---|---|
| 2’b01 | j型跳转 |
| 2’b10 | jr跳转 |
| 2’b11 | beq跳转 |
| 其他 | F_pc+4 |
注意事项
在计算j和beq指令跳转或分支到的下一条指令时,指令集说明中的pc+4为D_pc+4,而由于延迟槽的存在,如果顺序执行下一条指令,那么npc应该是F_pc+4,为延迟槽指令后的指令。
D_CMP
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| rs_data | input | [31:0] | 接收用来判断的rs的值 |
| rt_data | input | [31:0] | 接收用来判断的rt的值 |
| eq | output | 两值是否相等 |
注意事项
这里是实际上D级唯一需要除指令外数据的地方,rs、rt寄存器的值这里需要接收转发,除了W级的内部转发,还需要有M级的转发。接收转发的条件是来源级写入的目标寄存器和需要读的rs或rt寄存器相同。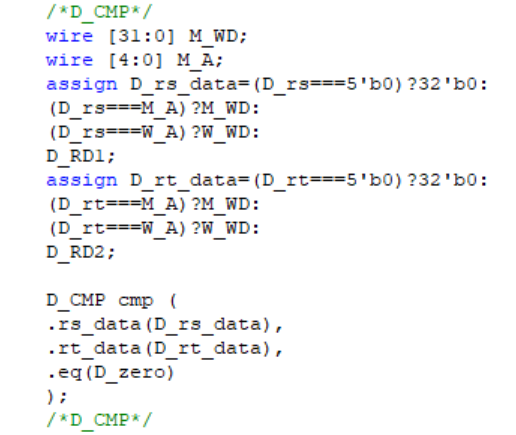
理解了D_CMP是D级唯一需要除指令外数据的地方,就可以明白E级向D级的转发是不必要的。如果D级的指令是beq,那么E级的指令不能是跳转和分支指令,因为课程文档里有这样的明确规定:“编译器保证延迟槽中的指令不能为分支或跳转指令。”所以如果存在E向D的转发,那么E级已有的数据一定有是D级需要的。这样的指令只能是jal,那么这就会产生矛盾。所以目前为了满足P5的要求,我们不需要E级向D级转发。
DE_REG
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| D_pc | input | [31:0] | 接收D的pc值 |
| D_instr | input | [31:0] | 接收D的机器码 |
| clear | input | 是否要清空寄存器中的值(阻塞添加气泡) | |
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| D_RD1 | input | [31:0] | D级读到的rs值 |
| D_RD2 | input | [31:0] | D级读到的rt值 |
| D_zero | input | D级得到的rs和rt是否相等的判断 | |
| D_EXT | input | [31:0] | D级得到的扩展后的值 |
| E_pc | output | [31:0] | 传递给E级的pc |
| E_instr | output | [31:0] | 传递给E级的机器码 |
| E_RD1 | output | [31:0] | 传递给E级的rs值 |
| E_RD2 | output | [31:0] | 传递给E级的rt值 |
| E_EXT | output | [31:0] | 传递给E级的扩展后结果 |
| E_zero | output | 传递给E级的是否相等的判断 |
当clear为1时,此时DE_REG被清空,相当于在当前的D级指令前插入了一个气泡。
E级
E_ALU
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| A | input | [31:0] | 第一个运算数 |
| B | input | [31:0] | 第二个运算数 |
| sll | input | [4:0] | sll移位的位数 |
| alu_op | input | [2:0] | 选择ALU进行的操作 |
| ans | output | [31:0] | 运算的结果 |
控制信号
| 信号 | 功能 |
|---|---|
| 3’b000 | A+B |
| 3’b001 | A-B |
| 3’b010 | AorB |
| 3’b011 | B<<sll |
| 3’b100 | B<<16(lui) |
| 其他 | 32’b0 |
注意事项
注意:
- E级从流水线寄存器读到的rs、rt值不是E级的rs、rt的值,还需要接收来自M级和W级的转发,因为此时的M级,也就是上一周期的E级在经过了E级后,有可能会得到新的值还未更新进寄存器,所以这个时候E级要接收M级和W级的转发,得到的才是真正的E级的rs和rt的值,也是接下来E级向M级传递的值。
- 进入ALU的运算数和E级的rs、rt寄存器的值并不相同。第二个运算数还可能是扩展后的立即数。
EM_REG
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| E_pc | input | [31:0] | 接收E的pc值 |
| E_instr | input | [31:0] | 接收E的机器码 |
| E_RD2 | input | [31:0] | 接收E的rt值 |
| E_alu_ans | input | [31:0] | 接收E计算出的计算结果 |
| E_zero | input | 接收E的判断结果(来自D) | |
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| M_pc | output | [31:0] | 传递给M级的pc |
| M_instr | output | [31:0] | 传递给M级的机器码 |
| M_RD2 | output | [31:0] | 传递给M级的rt值 |
| M_alu_ans | output | [31:0] | 传递给M级的ALU计算结果 |
| M_zero | output | 传递给M级的是否相等的判断 |
M级
M_DM
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| addr | input | [31:0] | 读或写的目标地址 |
| DataWrite | input | [31:0] | 写入DM的数据 |
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| dm_we | input | DM写使能信号 | |
| M_pc | input | [31:0] | M级的pc值 |
| ans | output | [31:0] | 读到或写入的值 |
MW_REG
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| clk | input | 时钟信号 | |
| reset | input | 复位信号 | |
| M_pc | input | [31:0] | M级的pc |
| M_instr | input | [31:0] | M级的instr |
| M_alu_ans | input | [31:0] | M级的ALU计算结果 |
| M_dm_read | input | [31:0] | M级的DM读到的数据 |
| M_zero | input | M级是否相等判断结果 | |
| W_pc | output | [31:0] | 传递给W级的pc |
| W_instr | output | [31:0] | 传递给W级的instr |
| W_alu_ans | output | [31:0] | 传递给W级的ALU计算结果 |
| W_dm_read | output | [31:0] | 传递给W级的DM中读到的数据 |
| W_zero | output | 传递给W级的是否相等的判断结果 |
zero信号的传递我发现是真没用,但是搭cpu的时候一直传过来了,也就懒得改了
关于CTRL和STALL,这两个模块和转发和阻塞关系紧密,于是放到数据通路分析再来介绍。
数据通路分析
除了上面的流水通路,我们还需要转发旁路和阻塞来保证流水线的正常运作。转发和阻塞都是我们为了解决冒险采取的策略。至于采用哪种策略,我们需要通过AT法来分析。A即判断前级数据来源寄存器和后级数据写入寄存器是否相等。T即判断T_use和T_new的大小关系,决定是否阻塞。根据课程组要求,在D级即判断是否阻塞,因此需计算D级的T_use。当T_use≥T_new时,说明在使用数据之前数据已经产生,所以此时可以转发,当T_use<T_new时,使用数据时数据还没有产生,此时必须阻塞。理论如此,但我们实际实现时可以采用无脑转发的策略。即不管T的关系,只要A满足了转发条件就转发,这样做是合理的原因在于:如果转发的数据是需要的,此时一定不会阻塞,如果此时发生了阻塞,那么转发过去的数据也是无用的。所以我们只需要判断是否阻塞即可。
阻塞
根据定义,我们可以得到T_use和T_new:
| 指令 | A(目标寄存器) | T_use_rs | T_use_rt | T_new_E | T_new_M | T_new_W |
|---|---|---|---|---|---|---|
| add | rd | 1 | 1 | 1 | 0 | 0 |
| sub | rd | 1 | 1 | 1 | 0 | 0 |
| sll | rd | 3 | 1 | 1 | 0 | 0 |
| ori | rt | 1 | 3 | 1 | 0 | 0 |
| lui | rt | 3 | 3 | 1 | 0 | 0 |
| beq | 0 | 0 | 0 | 0 | 0 | 0 |
| lw | rt | 1 | 3 | 2 | 1 | 0 |
| sw | 0 | 1 | 2 | 0 | 0 | 0 |
| j | 0 | 3 | 3 | 0 | 0 | 0 |
| jal | 31 | 3 | 3 | 0 | 0 | 0 |
| jr | 0 | 0 | 3 | 0 | 0 | 0 |
上表中,如果不需要数据则T_use为3,如果不产生数据则T_new为0。
T的产生,我们将其放在CTRL中产生,我们的CTRL采用分布式译码,每一流水级都有CTRL在,实例化时只需要读出所在级的T即可。
这里我们要有模块化思想,减少耦合,我们的CTRL只负责产生T,这一点根据指令即可做到。STALL模块负责使用T,判断是否要阻塞,不必考虑T从哪里来。所以模块间分工要明确,各司其职即可。引用wxm助教的话:
同样地,模块内部计算这些信号时,我们也不考虑上层如何使用这些信号,只需要在模块内部正确给出这些信号。 这样,我们考虑一条指令的转发逻辑时,再也不是”这是一条 jal 指令,它的 T_new 为 0,后续的指令无需阻塞,如果后续的指令写入地址为 31, 则需要将它的 pc + 8 转发给后续指令“。 而是这样:”这是一条 jal 指令,它的 T_new 为 0,写入地址为 31 , wData 为 pc + 8“;同时在上层我们发现:”D 级指令与某一级的指令地址均为 31,指令的 T_new <= T_use ,无需阻塞。使用该指令的 wData 。“这样,jal 的转发过程就完成了。
转发
其实转发只有有限的旁路,我们可通过表格整理出来:
| 转出 | 转入 |
|---|---|
| M级 | D级、E级 |
| W级 | D级、E级、M级 |
看起来相当的简单,当然,重要的是我们转发过去的数据是什么。我们从指令的角度考虑,转发的值都是寄存器的值,对于寄存器有操作的指令只有add、sub、sll、ori、lui、lw、jal。考虑在M级向D和E转发的值,这时不考虑lw,因为此时还没有产生数据,我们会发现除了jal,其他的值都是经过E级后ALU的计算结果,jal的转发值应该是M_pc+8(因为有延迟槽所以是+8)。所以M级的转发值只有这两种。同理,对于W级,多出的转发值只需要再加上W_dm_read即可。
接收转发时注意数据的优先级顺序,要优先接收来自较早层级的转发,防止接收本该被覆盖的值。
于是,考虑这样的情况,D级接收了来自M级的转发,则下个周期E级接收W级的转发,但这个时候W转发值的优先级已经不如M级高了,所以能保证我们转发机制的正确性。
CTRL和STALL的结构
CTRL
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| instr | input | [31:0] | 接收指令机器码 |
| npc_op | output | [1:0] | |
| alu_op | output | [2:0] | |
| grf_we | output | ||
| dm_we | |||
| ext_op | |||
| OpCode | output | [5:0] | |
| FuncCode | output | [5:0] | |
| rs | output | [4:0] | |
| rt | output | [4:0] | |
| rd | output | [4:0] | |
| shamt | output | [4:0] | |
| imm16 | output | [15:0] | |
| imm26 | output | [25:0] | |
| A | output | [4:0] | 写入的目标寄存器 |
| alu_slt | output | 1’b1则ALU的第二个操作数是扩展后的立即数,1’b0则是rt | |
| T_use_rs | output | [1:0] | |
| T_use_rt | output | [1:0] | |
| T_new_E | output | [1:0] | |
| T_new_M | output | [1:0] | |
| T_new_W | output | [1:0] | |
| jump_and_link | output | 跳转连接指令的标志,这标志着需要转发的值为pc+8 |
实例化时这些端口按需取用即可。
STALL
端口说明
| 端口 | input/output | 位宽 | 功能 |
|---|---|---|---|
| T_use_rs | input | [1:0] | |
| T_use_rt | input | [1:0] | |
| T_new_E | input | [1:0] | |
| T_new_M | input | [1:0] | |
| T_new_W | input | [1:0] | |
| D_rs | input | [4:0] | |
| D_rt | input | [4:0] | |
| E_A3 | input | [4:0] | E的写入目的寄存器 |
| M_A3 | input | [4:0] | M的写入目的寄存器 |
| stall | output | 阻塞信号 |
注意事项
判断是否阻塞时,只需要判断E和M是否影响D即可,因为W级可以内部转发将值给D,不会发生阻塞,当然也可以从AT的角度去看,W的T_new都是0,不会发生阻塞。
阻塞时,发生的操作为:
- 冻结pc(pc_we为0)
- 清空DE_REG(clear为1)
- 冻结FD(FD_we为0)
到这里我们的流水线CPU便可以搭建完成了
思考题
我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
答:把分支判断从E级提前到了D级,从AT法的角度来看可以认为使分支指令的T_use减少了1,这样更容易产生冒险并进行阻塞,所以并不是总能提高效率。例如
1
2
3
4
5ori $t1,1
sw $t1,0($zero)
lw $t2,0($zero)
add $0,$0,$0
beq $t1,$t2,lable如果在E级进行判断则是不需要阻塞的,而在D级进行判断则需要阻塞,导致效率的降低。
因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
答:因为有了延迟槽,对于 jal 等需要将指令地址写入寄存器的指令,其后的指令一定会紧跟执行,所以要写回的应该是延迟槽后的指令,也就是PC+8。
我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
答:功能部件基本上都是组合逻辑,存在延迟同时输出不稳定,从流水寄存器转发则可以避免。
我们为什么要使用 GPR 内部转发?该如何实现?
答:如果不进行内部转发,则在W和D产生数据冒险时,读到的结果会是错误的。
实现如下:1
2
3
4
5
6assign RD1=(A1===5'b0)?32'b0:
(A1===WR)?WD:
grf[A1];
assign RD2=(A2===5'b0)?32'b0:
(A2===WR)?WD:
grf[A2];我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
答:需求者来自于D、E、M,供给者来源于M、W。转发数据通路存在M向D、E的转发,转发数据为pc+8或alu_ans;W向D、E、M的转发,转发数据为pc+8或alu_ans或dm_read。
在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
答:可以把指令分为R型计算、I型计算、访存、分支跳转。
- 计算类指令需要更改CTRL、ALU
- 访存类指令需要更改CTRL、以及进入DM的输入通路
- 分支跳转类指令需要修改CTRL、NPC,同时注意转发通路。
确定你的译码方式,简要描述你的译码器架构,并思考该架构的优势以及不足。
答:采用了分布式译码,我认为,对于课程要求来说,分布式译码便于我们添加指令,如果有新的指令需要我们在某一级之后才能判断信号的值,分布式译码会让这样的过程更清晰;同时如果有新的控制信号出现,采用集中式译码需要在每一级流水线寄存器都添加新的端口;再加上我不喜欢把太多数据流水下去,更希望模块化独立化减少流水级之间的耦合,便于debug,所以选择采用分布式译码。好处是不需要把大量的控制信号流水,缺点是需要多次实例化控制器。
测试方案
手动构造数据,自动进行对拍。时间不充足(休息太久)没有随机生成数据,手动构造时采取分块构造的策略,每一部分指令验证某一功能,块与块之间联系几乎没有。对转发和阻塞进行着重验证。