【CO】P6课下--支持更多指令的流水线CPU
P6在P5基础上添加了更多的指令,相应地在结构上会有一些变化,本文为P6课下流水线CPU的设计思路和具体细节,仅供参考。
【CO】P6课下–支持更多指令的流水线CPU
设计方案
有了P5的流水线框架,P6的任务就更加有条理和清晰。P6的任务可以分为以下几点:
- 实现存储器外置
- 实现存储器支持按字节访存
- 实现乘除槽支持乘除相关指令
- 添加一些R型和I型指令
下面也就从这些任务出发对已有的流水线CPU进行改造。
实现存储器外置
存储器外置部分不需要我们自己实现,在课程组公开的mips_tb.v中我们可以了解输出的逻辑。存储器外置将CPU和IM、DM作为同等位置的模块,通过一些接口实现模块之间的数据交流。在这部分我们需要做的工作有删除GRF中的输出部分,删除IM和DM模块,将相关信息传递给要求中对应的接口。
在教程“在线测试相关说明”节下的“额外说明中”,“有些同学在 P5 中采用 AT 法后,不再需要使用 w_grf_we”指的是AT法在CTRL中对于不需要写入GRF的指令,将这部分指令的A设置为0,testbench中的输出逻辑为if (w_grf_we && (w_grf_addr != 0))所以只需要把w_grf_we设置为1就可以保证正常输出,当然保留CTRL中关于w_grf_we的判断也不会影响。
实现存储器支持按字节访存
要了解我们在字节使能模块(BE)和数据扩展模块(DE)中如何操作,我们还是应该先阅读testbench中的相关逻辑。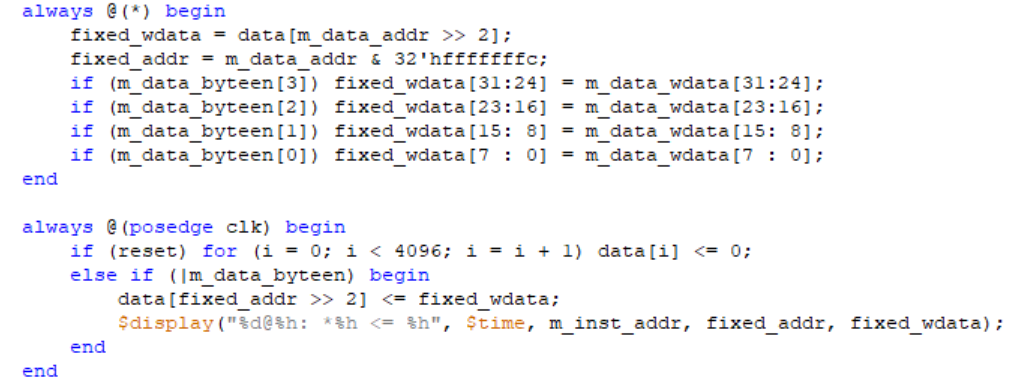
结合教程我们可以得到两个信息:
- 在BE中需要输出字节使能信号和待写入的数据
- 之前的dm_we信号不再需要,对于非存入指令只需要将其m_data_byteen设置为4’b0000
同时还有最重要的一点:我们将一个word分为四个byte对每一个byte考虑,这一点是我们处理访存指令的关键。我们还可以发现实际上我们对访问和存取进行了分离,存取指令所需要的信号和数据都由BE产生,访问指令得到的数据由DE产生,这样做也正满足课程组要求的高内聚低耦合,减少了指令间的耦合。
BE实现思路
BE模块是为store类指令服务的,需要输出4位字节使能信号和待写入数据。根据指令和操作内存的地址,我们可以得到对应位上的字节使能信号,如sb指令操作的内存地址后两位是2’b01,那么输出的字节使能信号即为4’b0010。之所以只看操作内存地址的后两位是因为字节已经是操作的最小单位,后两位已经足够为我们指示要操作的字节位置。也可以这样理解:我们根据前30位找到了待操作的字(字对齐的原理),然后再根据后两位确定需要操作的字节。
对于待写入数据,我们可以通过位拼接输出32位的数据,我们读取到的数据缺失的部分我们可以用任意的数来填充,因为根据testbench我们可以知道,只会根据byteen信号把有效位置的字节进行写入,所以其他位置是什么并不重要。
DE实现思路
DE模块是为load类指令服务的,需要将读到的数据按要求进行扩展。对于进入模块的32位读到的数据,我们根据地址后两位确定我们要读的数据部分进行截取,可以通过宏定义的方式来实现:
1 | |
之后根据指令要求分别进行扩展即可。
实现乘除槽支持乘除相关指令
首先我们把乘除指令进行分类:
- md类:mult、multu、div、divu
- mf类:mflo、mfhi
- mt类:mtlo、mthi
只有这些指令需要进入MDU模块,我们可以认为MDU和ALU是并行的,这样可以帮助我们更好地理解乘除指令的阻塞。
首先我们明确,乘除指令和其他指令没有区别,都是每个时钟周期向下流水一级(非阻塞),这样在md类的指令到达E级时,MDU模块接收到start信号开始进行乘除操作,由于我们需要模拟乘除操作的延迟,我们不能立刻将得到的答案存入HI和LO寄存器中,可以先暂存,等busy结束后立刻存入。虽然MDU在忙着进行好几个周期的计算,但指令并不是在这里等着MDU计算,而是下一时钟周期就流水到了下一级,那么我们会有这样的问题:如果前面的流水级需要md指令的计算结果那么该怎么办呢?md指令在向下流水的过程中并没有把自己的结果打包打走啊?首先需要md指令的计算结果需要通过mf指令把结果转移到GRF中的普通寄存器,所以md类指令在M、W级不会作为转发的来源。那么为了保证mf指令能将HI、LO中的值正确地转移到GRF中,当MDU处于start或busy状态时mf指令必须阻塞在D级。同样为了保证mt指令能将HI、LO寄存器正确更新,mt类指令也应在相同情况下阻塞在D级。所以阻塞条件应该在原基础上添加乘除指令带来的阻塞,选择在顶层模块进行添加,不对STALL模块内部调整(不想加接口…)。
对于md和mt类指令,需要接收转发,通过AT法实现即可。对于mf类指令,可能会作为转发的来源,因此在M级和W级进行转发时需要添加新的选择,即乘除类指令转发MDU结果,将该结果在流水线寄存器中流水传递下去并在转发时判断当前级是否为mf类指令即可。
总结一下,E级MDU处于start或busy状态,D级如果是乘除指令(md、mt、mf)那么阻塞直到计算完成;md和mt需要接收转发,通过AT法实现即可;mf需要作为来源进行转发,转发来源增添MDU的结果。新增的乘除指令不会从E级向D级转发,因为其经过D级并没有得到什么更多的有用的信息。
添加R型和I型指令
支持的指令集包括:
1 | |
显然我们把这些指令进行分类会极大提高控制信号驱动译码时的可读性和准确性,同时添加新指令时也会更加清晰,因此我们在CTRL中对这些指令进行分类:
1 | |
这是该部分我们做的最重要的工作,剩余的工作便是将ALU和NPC进行扩展以支持新指令,并将CTRL中的控制信号由指令类型进行驱动。
思考题
- 为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
答:乘除法运算需要的硬件复杂性更高同时计算的延迟更大,如果整合进ALU中,会导致ALU处的关键路径延迟增大,降低整体的性能;将乘除法部件抽离出来有助于降低延迟,同时可以与ALU并行运算,提高效率。独立的HI、LO寄存器可以使乘除法的设计更加清晰,指令集的设计中不需要对通用寄存器再进行额外的管理,同时可以减少乘除法导致的流水线冲突,提高运行效率。
- 真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
答:现代流水线CPU主要有迭代方法和流水线方法两种实现方式。迭代方法基于逐步的加法和移位操作完成乘法,或者使用减法和移位完成除法。优点在于设计简单,面积占用小,只需要32位加法器和一些逻辑电路,缺点是执行速度较慢,适合乘除法指令占比低的情况。流水线方法将乘法或除法操作分解为多个流水线阶段,如部分积生成、部分积归并等,可以在流水线中同时处理多条指令。处理效率高,适合乘除法指令较多的情况,缺点在于硬件复杂度高。
- 请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
答:E级如果处于Busy或Start状态,如果D级指令为乘除法相关的指令,则阻塞在D级直到E级完成了计算。
- 请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
答:字节使能信号使写操作能准确控制字节的写入,每个字节是否写通过该位是否是1可以清晰判断,避免了错误的数据覆盖,调试时也只需要关心特定位置的字节而不需要考虑对齐和其他问题。同时字节使能信号使对多种宽度的数据的修改统一起来,便于扩展,在实际硬件设计的时候内存模块也可以实现统一设计。同时在性能上,字节使能信号能够支持对不同字节的并行修改,相较于逐个字节修改提高了内存的读写效率。
- 请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
答:不是一字节,而是32位的字,再根据指令对我们需要的字节进行操作。在数据体积较小同时对延迟比较敏感的时候,按字节读写可以减少不需要的数据读写,从而降低由此产生的延迟,提高效率。
- 为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
答:(1)根据指令类型和指令行为对指令进行分类,译码时使指令对应的信号能够更清晰,在添加新指令时也能根据其类型快速译码而不需要逐个添加,处理数据冲突时根据指令行为可以迅速判断转发和阻塞策略,思路会更加直观。(2)模块间高内聚低耦合,减少模块间的耦合,在顶层数据通路中传递信号,使顶层通路更清晰,模块间各司其职,也便于调试和问题定位。(3)规范模块和信号命名,不同流水级信号和模块在命名中体现出来,使数据传递通路更清晰。
- 在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
答:乘除指令与乘除指令、计算指令、分支指令、跳转链接指令、访存指令。通过AT法实现阻塞和转发解决冲突。
测试样例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28ori $t1,$0,1
ori $t2,$0,2
ori $t3,$0,3
ori $t4,$0,4
ori $t5,$0,5
mult $t3,$t4
mflo $t5
sw $t5,0($t4)
lw $t6,0($t4)
add $t5,$t2,$t3
beq $t5,$t4,lable2
ori $t1,$0,1
ori $t2,$0,2
ori $t3,$0,3
ori $t4,$0,4
ori $t5,$0,5
mult $t6,$t6
mflo $t7
ori $t7,$0,7
ori $t7,$0,8
mthi $t7
jal lable
ori $t8,$0,8
ori $t9,$0,9
lable:
mult $ra,$t1
lable2:
ori $0,$0,0 - 如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
答:手动构造样例,分块构造,例如将分支指令放在D级测试阻塞,E级放一个计算指令,M级放一个访存指令,这样可以测试阻塞功能是否正常,然后用五个ori指令重置流水线,实现分块。这样分别测试不同情况下产生的数据冲突是否能正确解决。